
John Winkley, AlphaPlus’ Director of Business Development, explains how assessment theory and performance statistics can be used to create “good” assessments.
AlphaPlus has a reasonable claim to be the leading independent assessment agency in the United Kingdom. Our team includes a range of experts in the field, and we carry out projects across the whole spectrum of educational assessment, from primary school tests to postgraduate professional examinations.
We aim to help organisations make their educational assessments better. Wherever assessments are used, and whatever the purpose, good assessments make sure that people get the outcome they deserve: the right people pass and fail; the grades awarded are fair; the results are honest, reliable and defensible, and reflect the attributes that stakeholders value.
Over recent weeks, a number of projects have led me to think about what we’ve been busy with over the last decade or so, so in this short piece I’m taking a look at two areas of assessment design that come up all the time and as a result can sometimes be overlooked. AlphaPlus’ clients expect us to combine deep knowledge of assessment theory with a practicality and focus on making real improvements to real assessments in a risk-averse environment (ie not improving one aspect of the assessment at the expense of an important other).
Assessment design almost always involves compromises. The most common compromises we see are around the triangle in the diagram below. This is clearly not a purist’s view (reliability is subsumed within validity, for a start), but it reflects everyday challenges for certification bodies: a longer test will likely improve internal reliability and content validity to the detriment of operational cost and practicability, for example.
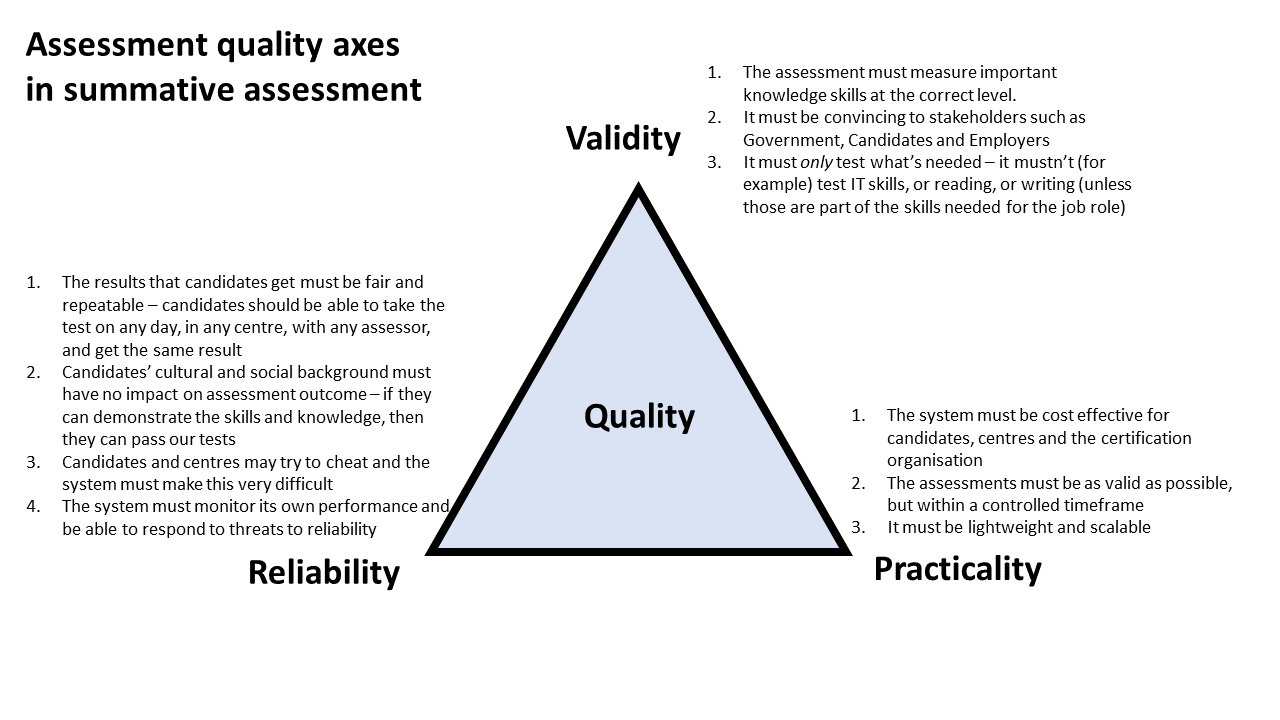
We often find ourselves discussing assessment design options with clients, and these discussions can often seem like an ever-growing swirl of options, with each further step down the assessment theory rabbit hole adding new complexity to the decision making. While trialling new assessments remains the best option, followed by post-release qualitative and quantitative performance studies, documenting the “design compromises” can help remind assessment designers about the choices they made when considering how a live assessment is working, and what improvements to make next.
Many AlphaPlus conference presentations over the last decade have had a common theme of “make better use of assessment performance statistics”. So often, practicalities mean that assessments have to be launched without the opportunity for adequate trials or validity studies. Performance data provides an essential way to get rapid feedback on how new tests are performing, and to direct scarce resources toward improvement. The acceptance of the need for continuous improvement and the pace of the improvement cycle is often more important than the quality of the initial assessments from the perspective of overall validity.
One assessment data lesson that comes around time and again, highlights one of the biggest and most fundamental challenges – writing good questions. This sounds obvious – and it is! Alistair Pollitt’s bucket brigade analogy [1] – “validity (water) in the assessment development and delivery chain (the bucket chain) can only be retained or lost, not added” – helps to clarify. Good assessment specifications, strong writing teams, cycles of review, and, of course, trials have helped make “writing good questions” less of a craft and more of a manageable process, but even the best teams and processes can throw up surprises.
The challenge to move many vocational assessments from minimum competence to graded models, with the associated challenge of defining what a level means, and how to align it to a test score reminded me of a project we ran some years ago where the challenge was to write questions for a high stakes test where the questions had to be targeted at the grade descriptors for GCSE mathematics (An “A grade” student ‘can do’ the following, A “B” grade student ‘can do’ the following, etc.). We assembled the best maths test writers we had, organised them into peer review teams, with cycles of QA, and asked them to write “easy”, “medium” and “hard” questions. The result is shown in the chart below.
Many of the designated “easy questions” were harder than most of the “medium questions” and several of the “hard questions”, and so on.
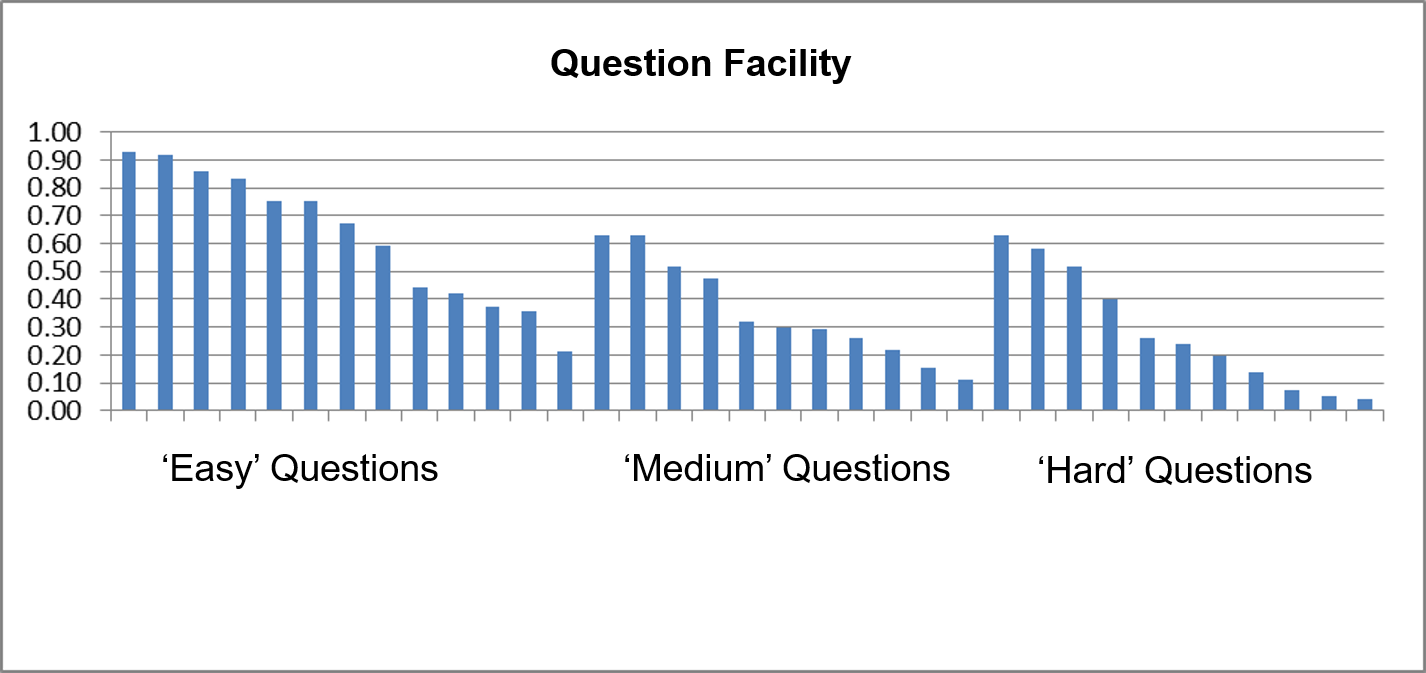
After much analytics, looking back at previous assessment cycles, reworking of test content, etc., we concluded that we had probably done a reasonable job against a tricky assessment specification. The questions performed well in terms of difficulty and discrimination, but not entirely as predicted. Subsequent writing cycles fitted the model better. This highlights for me two really important messages:
- Assembling good writing teams, and providing processes that support their work with multiple QA cycles is as critically important as ever in maximising the chance of good assessment outcomes.
- Trusting assessment writers to know the difficulty of their questions makes you (the assessment owner) a hostage to fortune. Assessment data provides both the acid test and the process feedback which is critical to improving quality over time.
Notes
[1] For example https://www.sqa.org.uk/sqa/files_ccc/CreatingValidAssessmentsForCfE.pdf


